 All orders Built, Shipped & Supported from within the European Union
All orders Built, Shipped & Supported from within the European Union
All orders Built, Shipped & Supported from within the European Union
All orders Built, Shipped & Supported from within the European Union
NVIDIA based GPU optimised servers for AI, Deep Learning and HPC - configurable with up to 10x GPU's for massively parallel computing.
Deployed by some of the planets largest supercomputing enterprises, NVIDIA are the worlds leading platform for accelerating data centres. Key to this platform is the hugely parallel PU accelerators that provide massively improved throughput for compute-intensive workloads - without increasing cost and physical footprint.



Supports 1x double slot GPU card, 5th/4th Gen Intel Xeon Scalable processor, dual 1Gb/s LAN ports, redundant power supply, 4x 3.5" NVMe/SATA hot-swappable bays

Supports 1x double slot GPU card, 5th/4th Gen Intel Xeon Scalable processor, dual 1Gb/s LAN ports, redundant power supply, 10x 2.5" NVMe/SATA hot-swappable bays

Supports 1x double slot GPU card, 5th/4th Gen Intel Xeon Scalable processor, dual 1Gb/s LAN ports, redundant power supply, 8x 3.5" NVMe/SATA hot-swappable bays

Supports up to 3x double slot Gen5 GPU cards, single 1Gb/s LAN port, redundant power supply, 12 x 3.5/2.5" SATA/SAS hot-swappable bays, 5th/4th Gen Intel Xeon Scalable processor

5th/4th Gen Intel Xeon Scalable processor, single 1Gb/s LAN port, redundant power supply, 2x 2.5" NVMe/SATA hot-swappable bays

NVIDIA DGX Spark Founders Edition AI Supercomputer. Designed for a development, pre-production and concept that allows developers to test and fine tune AI Code / software stack prior to AI Production.

Dual 5th/4th Gen Intel Xeon Scalable Gen4 Processor, GPU Computing Pedestal Supercomputer Server, 4x Tesla, RTX GPU Cards

Single AMD EPYC 9005 / 9004 Series, Supports up to 4x FHFL PCIe Gen5 x16 slots - 12x 3.5"/2.5" NVMe/SAS/SATA Drives.

Single AMD EPYC 9005 / 9004 Series, Supports up to 4x FHFL PCIe Gen5 x16 slots - 4x 2.5" NVMe/SAS/SATA & 4x 2.5" SAS/SATA Drives.

Supports up to 8x double slot Gen4 GPU cards, dual 10Gb/s BASE-T LAN ports, redundant power supply, 8x 2.5" NVMe/SATA hot-swappable bays. Built for AI & HPC
Single AMD EPYC 9005 / 9004 Series, Supports up to 8x FHFL PCIe Gen5 x16 slots - 4x 2.5" NVMe/SAS/SATA & 4x 2.5" SAS/SATA Drives.

Dual Intel Xeon 6 Series processors, dual 10Gb/s LAN ports, redundant power supply, 8x 2.5" NVMe/SATA/SAS hot-swappable bays.
Single AMD EPYC 9005 / 9004 Series, Supports up to 8x FHFL PCIe Gen5 x16 slots - 4x 2.5" NVMe/SAS/SATA & 4x 2.5" SAS/SATA Drives.

Dual AMD EPYC 9005 / 9004 Series, Supports up to 4x dual-slot Gen5 GPUs - 4x 2.5" NVMe/SATA & 4x SATA Drives.

Short Depth Dual AMD EPYC 9005 / 9004 Series Server with 4x GPU Slots, 6x 2.5" Gen4 NVMe Hot-Swappable bays
Short Depth Dual AMD EPYC 9005 / 9004 Series Server with 4x GPU Slots, 6x 2.5" Gen4 NVMe Hot-Swappable bays

Dual Intel Xeon 6 Series processors, Supports 8x Dual slot Gen5 GPUs, dual 10Gb/s LAN ports, redundant power supply, 12x 2.5" NVMe/SATA/SAS & 4x SATA/SAS hot-swappable bays.

Supports 10x double slot GPU cards, dual 10Gb/s BASE-T LAN ports, redundant power supply, 12x 3.5/2.5" NVMe/SATA hot-swappable bays. Built for AI & HPC

Dual AMD EPYC 9005 / 9004 Series 8x GPU Server - 20x 2.5" SATA / SAS + 4x NVMe Dedicated Drives

Dual AMD EPYC 9005 / 9004 Series, Supports up to 8x FHFL PCIe Gen5 x16 slots - 4x 2.5" NVMe/SATA/SAS & 4x SATA/SAS Drives.

Dual Intel Xeon 6 Series processors, Supports 8x Dual slot Gen5 GPUs, dual 10Gb/s LAN ports, redundant power supply, 12x 2.5" NVMe/SATA/SAS & 4x SATA/SAS hot-swappable bays.
Dual AMD EPYC 9005 / 9004 Series, Supports up to 8x FHFL PCIe Gen5 x16 slots - 4x 2.5" NVMe/SATA/SAS & 4x SATA/SAS Drives.

Dual AMD EPYC 9005 / 9004 Series 8x GPU Server - 4x 2.5" NVMe/SATA/SAS & 4x SATA/SAS

Dual AMD EPYC 9005 / 9004 Series 8x GPU Server - 12x 2.5" NVMe/SATA/SAS

Single AMD EPYC 9005 / 9004 Series Server with 4x GPU Slots, 2x 2.5" Gen4 NVMe Hot-Swappable bays
Dual AMD EPYC 9005 / 9004 Series 8x GPU Server - 12x 2.5" NVMe/SATA/SAS

Dual Intel Xeon 6 Series processors, Supports 8x Dual slot Gen5 GPUs, dual 10Gb/s LAN ports, redundant power supply, 8x 2.5" NVMe hot-swappable bays.

Supports 4x SXM5 GPU Modules, dual 10Gb/s BASE-T LAN ports, redundant power supply, 8x 2.5" NVMe/SATA hot-swappable bays. Built for AI & HPC

Supports 8x HGX H200 GPUs, dual 10Gb/s BASE-T LAN ports, redundant power supply, 16 x 2.5" NVMe, 8x SATA hot-swappable bays. Built for AI Training and Inferencing.

Supports 8x HGX H200 GPUs, Dual AMD EPYC 9004 Series 8x GPU Server - 16x 2.5" NVMe + 8x SATA Drives Hot-Swappable bays. Built for AI Training and Inferencing.

NVIDIA DGX H200 with 8x NVIDIA H200 141GB SXM5 GPU Server, Dual Intel® Xeon® Platinum Processors, 2TB DDR5 Memory, 2x 1.92TB NVMe M.2 & 8x 3.84TB NVMe SSDs.

CyberServe Xeon SP2-808S G6 with 8x NVIDIA HGX B300 GPUs, Dual Intel Xeon 6 Series Processors, DDR5 Memory, 2x M.2 slots & 8x NVMe Hot swap drive bays

Dual Intel Xeon 6700/6500-Series processors, Liquid-cooled NVIDIA HGX B300, dual 10Gb/s LAN ports, redundant power supply, 8x 2.5" NVMe hot-swappable bays.

Dual AMD EPYC 9005/9004 Server Processors, Liquid-cooled NVIDIA HGX B300, 8x 800 Gb/s OSFP XDR InfiniBand or dual 400 Gb/s Ethernet ports, redundant power supply, 8x 2.5" NVMe hot-swappable bays.
NVIDIA DGX B200 with 8x NVIDIA Blackwell GPUs, Dual Intel® Xeon® Platinum 8570 Processors, 4TB DDR5 Memory, 2x 1.92TB NVMe M.2 & 8x 3.84TB NVMe SSDs.

NVIDIA DGX B300 with 8x NVIDIA Blackwell Ultra SXM GPUs, Dual Intel® Xeon® 6776P Processors, 2TB DDR5 Memory, 2x 1.92TB NVMe M.2 & 8x 3.84TB E1.S NVMe.

NVIDIA DGX GB200 with 72x NVIDIA Blackwell GPUs, Dual Intel® Xeon® Platinum Processors, 4TB DDR5 Memory, 2x 1.92TB NVMe M.2 & 8x 3.84TB NVMe SSDs.

NVIDIA L4 | NVIDIA RTX6000 ADA | NVIDIA L40S | NVIDIA H100 | NVIDIA GH200 | |
|---|---|---|---|---|---|
| Application | Virtualised Desktop, Graphical and Edge Applications | High-end Design, Real-time Rendering, High-performance Compute Workflows | Multi-modal Generative AI, and Graphics and Videos Workflows | LLMs Inference, AI and Data Analytics | Generative AI, LLMs Inference, and Memory Intensive Applications |
| Architecture | Ada Lovelace | Ada Lovelace | Ada Lovelace | Hopper | Grace Hopper |
| SMs | 60 | 142 | 142 | 114 | 144 |
| CUDA Cores | 7,424 | 18,176 | 18,176 | 18,432 | 18,432 |
| Tensor Cores | 240 | 568 | 568 | 640 | 576 |
| Frequency | 795 Mhz | 915 MHz | 1,110 Mhz | 1,590 MHz | 1,830 MHz |
| FP32 TFLOPs | 30.3 | - | 91.6 | 51 | 67 |
| FP16 TFLOPs | 242 | 91.1 | 733 | 1,513 | 1,979 |
| FP8 TFLOPs | 485 | - | 1,466 | 3,026 | 3,958 |
| Cache | 48 MB | 96 MB | 48 MB | 50 MB | 60 MB |
| Max. Memory | 24 GB | 48 GB | 48 GB | 80 GB | 512 GB |
| Memory B/W | 300 GB/s | 960 GB/s | 864 GB/s | 2,000 Gb/s | 546 GB/s |
The NVIDIA L4 Tensor Core GPU, built on the NVIDIA Ada Lovelace architecture, offers versatile and power-efficient acceleration across a wide range of applications, including video processing, AI, visual computing, graphics, virtualisation, and more. Available in a compact low-profile design, the L4 provides a cost-effective and energy-efficient solution, ensuring high throughput and minimal latency in servers spanning from edge devices to data centers and the cloud.

The NVIDIA L4 is an integral part of the NVIDIA data center platform. Engineered to support a wide range of applications such as AI, video processing, virtual workstations, graphics rendering, simulations, data science, and data analytics, this platform enhances the performance of more than 3,000 applications. It is accessible across various environments, spanning from data centers to edge computing to the cloud, offering substantial performance improvements and energy-efficient capabilities.
As AI and video technologies become more widespread, there's a growing need for efficient and affordable computing. NVIDIA L4 Tensor Core GPUs offer a substantial boost in AI video performance, up to 120 times better, resulting in a remarkable 99 percent improvement in energy efficiency and lower overall ownership costs when compared to traditional CPU-based systems. This enables businesses to reduce their server space requirements and significantly decrease their environmental impact, all while expanding their data centers to serve more users. Switching from CPUs to NVIDIA L4 GPUs in a 2-megawatt data center can save enough energy to power over 2,000 homes for a year or offset the carbon emissions equivalent to planting 172,000 trees over a decade.
As AI becomes commonplace in enterprises, organizations need comprehensive AI-ready infrastructure to prepare for the future. NVIDIA AI Enterprise is a complete cloud-native package of AI and data analytics software, designed to empower all organizations in excelling at AI. It's certified for deployment across various environments, including enterprise data centers and the cloud, and includes global enterprise support to ensure successful AI projects.
NVIDIA AI Enterprise is optimised to streamline AI development and deployment. It comes with tested open-source containers and frameworks, certified to work on standard data center hardware and popular NVIDIA-Certified Systems equipped with NVIDIA L4 Tensor Core GPUs. Plus, it includes support, providing organizations with the benefits of open source transparency and the reliability of global NVIDIA Enterprise Support, offering expertise for both AI practitioners and IT administrators.
NVIDIA AI Enterprise software is an extra license for NVIDIA L4 Tensor Core GPUs, making high-performance AI available to almost any organization for training, inference, and data science tasks. When combined with NVIDIA L4, it simplifies creating an AI-ready platform, speeds up AI development and deployment, and provides the performance, security, and scalability needed to gain insights quickly and realize business benefits sooner.
The new NVIDIA RTX 6000 Ada Generation delivers the features, capabilities, and performance needed to tackle the tasks of modern professional workflows. Using the latest NVIDIA Ada Lovelace GPU architecture, it comes with advanced features and powerful performance. With upgraded RT Cores, Tensor Cores, and CUDA cores, along with 48GB of graphics memory, it offers exceptional rendering, AI processing, graphics work, and computing power. Workstations powered by the NVIDIA RTX 6000 are equipped to help you thrive in today's tough business world..
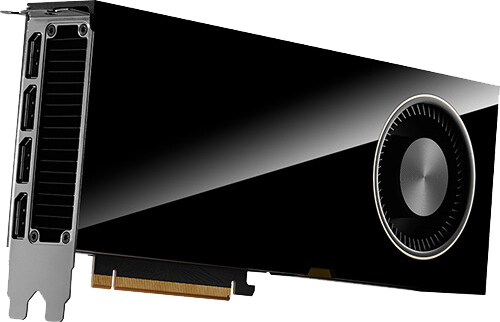
The NVIDIA RTX 6000 Ada Generation is the ultimate workstation graphics card designed for professionals who need top-notch performance and reliability to deliver their highest quality work and revolutionary advancements across industries. It offers unmatched performance and capabilities crucial for demanding tasks like high-end design, real-time rendering, AI, and high-performance computing.
Built on the NVIDIA Ada Lovelace architecture, the RTX 6000 merges 142 third-gen RT Cores, 568 fourth-gen Tensor Cores, and 18,176 CUDA cores with 48GB of ECC graphics memory. This combination powers the next era of AI graphics and petaflop inferencing performance, leading to remarkable acceleration in rendering, AI, graphics, and compute workloads.
NVIDIA RTX professional graphics cards are certified for use with an extensive range of professional applications. They've been tested by top independent software vendors (ISVs) and workstation makers and are supported by a global team of experts. With this reliable visual computing solution, you can focus on your important tasks without worries.
Unlock remarkable multi-tasking performance with the NVIDIA L40S GPU. This GPU merges potent AI computing with top-tier graphics and media speed, designed to fuel upcoming data center tasks. From advanced AI and language model processing to 3D graphics, rendering, and video tasks, the L40S GPU is primed for the next level of performance.

Hardware support for structural sparsity and optimised TF32 format offer immediate performance improvements for quicker AI and data science model training. Accelerate AI-enhanced graphics capabilities with DLSS to upscale resolution with improved performance in specific applications.
Improved throughput and concurrent ray-tracing and shading capabilities enhance ray-tracing performance, speeding up renders for product design, architecture, engineering, and construction tasks. Experience realistic designs with hardware-accelerated motion blur and impressive real-time animations.
The Transformer Engine significantly speeds up AI tasks and enhances memory usage for both training and inference. Using the Ada Lovelace fourth-generation Tensor Cores, Transformer Engine intelligently scans the layers of transformer architecture neural networks and automatically recasts between FP8 and FP16 precisions to boost AI performance and accelerate training and inference.
The L40S GPU is fine-tuned for 24/7 enterprise data center operations, and designed,built, tested, and supported by NVIDIA to guarantee top-notch performance, longevity, and operational stability. The L40S GPU meets the latest data center standards, is ready for Network Equipment-Building System (NEBS) Level 3 ready, and features secure boot with root of trust technology, enhancing data center security.
The medium of online video is quite possibly the number one way of delivering information in the modern age. As we move forward into the future, the volume of online videos will only continue to grow exponentially. Simultaneously, the demand for answers to how to efficiently search and gain insights from video continues to grow.
T4 provides ground-breaking performance for AI video applications, featuring dedicated hardware transcoding engines which deliver 2x the decoding performance possible with previous-generation GPUs. T4 is able to decode up to nearly 40 full high definition video streams, making it simple to integrate scalable deep learning into video pipelines to provide inventive, smart video services.
Experience remarkable performance, scalability, and security for all tasks using the NVIDIA H100 Tensor Core GPU. The NVIDIA NVLink Switch System allows for connecting up to 256 H100 GPUs to boost exascale workloads. This GPU features a dedicated Transformer Engine to handle trillion-parameter language models. Thanks to these technological advancements, the H100 can accelerate large language models (LLMs) by an impressive 30X compared to the previous generation, establishing it as the leader in conversational AI.

NVIDIA H100 GPUs for regular servers include a five-year software subscription that encompasses enterprise support for the NVIDIA AI Enterprise software suite. This simplifies the process of adopting AI while ensuring top performance. It grants organizations access to essential AI frameworks and tools to create H100-accelerated AI applications, such as chatbots, recommendation engines, and vision AI. Take advantage of the NVIDIA AI Enterprise software subscription and its associated support for the NVIDIA H100.
The NVIDIA H100 GPUs feature fourth-generation Tensor Cores and the Transformer Engine with FP8 precision, solidifying NVIDIA's AI leadership by achieving up to 4X faster training and an impressive 30X speed boost for inference with large language models. In the realm of high-performance computing (HPC), the H100 triples the floating-point operations per second (FLOPS) for FP64 and introduces dynamic programming (DPX) instructions, resulting in a remarkable 7X performance increase. Equipped with the second-generation Multi-Instance GPU (MIG), built-in NVIDIA confidential computing, and the NVIDIA NVLink Switch System, the H100 provides secure acceleration for all workloads across data centers, ranging from enterprise to exascale.
The NVIDIA Pascal architecture enables the Tesla P100 to deliver superior performance for HPC and hyperscale workloads. With more than 21 teraflops of FP16 performance, Pascal is optimised to drive exciting new possibilities in deep learning applications. Pascal also delivers over 5 and 10 teraflops of double and single precision performance for HPC workloads.
The NVIDIA H100 is a crucial component of the NVIDIA data center platform, designed to enhance AI, HPC, and data analytics. This platform accelerates more than 3,000 applications and is accessible across various locations, from data centers to edge computing, providing substantial performance improvements and cost-saving possibilities.
The NVIDIA GH200 Grace Hopper Superchip is a revolutionary high-speed CPU built specifically for massive AI and high-performance computing (HPC) tasks. This superchip boosts performance by up to 10 times for applications running terabytes of data, enabling scientists and researchers to find groundbreaking solutions to the toughest global challenges.

The NVIDIA Grace Hopper architecture combines the innovative power of the NVIDIA Hopper GPU and the flexibility of the NVIDIA Grace CPU into one advanced superchip. This integration is facilitated by the NVIDIA NVLink Chip-2-Chip (C2C) interconnect, ensuring high-bandwidth and memory coherence between the two components. This unified architecture maximises performance and efficiency, enabling seamless collaboration between GPU and CPU for a wide range of computing tasks.
NVIDIA NVLink-C2C is a memory-coherent, high-bandwidth, and low-latencyinterconnect for superchips. At the core of the GH200 Grace Hopper Superchip, it provides up to 900 gigabytes per second (GB/s) of bandwidth, which is 7 times faster than PCIe Gen5 lanes commonly used in accelerated systems. NVLink-C2C allows applications to use both GPU and CPU memory efficiently. With up to 480GB of LPDDR5X CPU memory per GH200 Grace Hopper Superchip, the GPU has direct access to 7X more fast memory than HMB3 or almost 8X more fast memory with HBM3e. GH200 can be used in standard servers to run a variety of inference, data analytics,and other compute and memory-intensive workloads. GH200 can also be combined with the NVIDIA NVLink Switch System, with all GPU threads running on up to 256 NVLink-connected GPUs and able to access up to 144 terabytes (TB) of memory at high bandwidth.
The NVIDIA Grace CPU offers twice the performance per watt compared to traditional x86-64 platforms and stands as the fastest Arm data center CPU worldwide. It's designed for high single-threaded performance, high- memory bandwidth, outstanding data-movement capabilities. The NVIDIA Grace CPU combines 72 Neoverse V2 Armv9 cores and up to 480GB of server-grade LPDDR5X memory with ECC, it achieves an optimal balance between bandwidth, energy efficiency, capacity, and cost. Compared to an eight-channel DDR5 design, the Grace CPU's LPDDR5X memory system delivers 53 percent more bandwidth while using only one-eighth the power per gigabyte per second.
The H100 Tensor Core GPU is NVIDIAs latest data center GPU, offering a significant performance boost for large-scale AI and HPC compared to the previous A100 Tensor Core GPU. Built on the new Hopper GPU architecture, the NVIDIA H100 introduces several innovations:
The GH200 Grace Hopper Superchip marks the first genuine mixed accelerated platform tailored for HPC tasks. It boosts any application by leveraging the strengths of both GPUs and CPUs, all while offering the simplest and most efficient mixed programming approach yet. This allows scientists and engineers to concentrate on tackling the world's most pressing issues. For AI inference workloads, GH200 Grace Hopper Superchips combines with NVIDIA networking technologies to offer the most cost-effective scaling solutions, empowering users to handle larger datasets, more intricate models, and new tasks with access to up to 624GB of high-speed memory. For AI training, up to 256 NVLink-connected GPUs can access up to 144TB of memory at high bandwidthfor large language model (LLM) or recommender system training.
Broadberry GPU Servers harness the processing power of NVIDIA Ada Lovelace & Hopper graphics processing units for millions of applications such as image and video processing, computational biology and chemistry, fluid dynamics simulation, CT image reconstruction, seismic analysis, ray tracing, and much more.
As computing evolves, and processing moves from the CPU to co-processing between the CPU and GPU's, NVIDIA invented the CUDA parallel computing architecture to harness the performance benefits.
Speak to Broadberry GPU computing experts to find out more.

 Our Rigorous Testing
Our Rigorous TestingBefore leaving our UK workshop, all Broadberry server and storage solutions undergo a rigorous 48 hour testing procedure. This, along with the high-quality industry leading components ensures all of our server and storage solutions meet the strictest quality guidelines demanded from us.
 Un-Equaled Flexibility
Un-Equaled FlexibilityOur main objective is to offer great value, high-quality server and storage solutions, we understand that every company has different requirements and as such are able to offer un-equaled flexibility in designing custom server and storage solutions to meet our clients' needs.
We have established ourselves as one of the biggest storage providers in the UK, and since 1989 supplied our server and storage solutions to the world's biggest brands. Our customers include:


CyberServe Ryzen RY1-104A
A core-heavy Ryzen rack server at an entry-level price ...
| April 01, 2024
CyberServe Xeon SP1-102G NVMe G5
A small, powerful, and affordable rack server.
Broadberry gets edgy with a great value rack server...
| December 01, 2023
Intel M50CYP2UR208 Coyote Pass Server - 8 Drive Bays. SAS/SATA/NVME
A mighty server package for the price with a big helping of blisteringly fast Intel Optane 200 PMEMs...
| August 02, 2021
Broadberry CyberStore Xeon SP2-490-G3
A big storage appliance for big data with a powerful hardware package and great performance...
| December 05, 2022
Call Our EU Sales Team Now| German / English: | +49 89 1208 5600 |
| French / English: | +33 1 72 81 06 78 |
 Artificial Intelligence Server for HMRC Fraud Detection
Artificial Intelligence Server for HMRC Fraud Detection  Ultra-Performance AI Server for Samsung
Ultra-Performance AI Server for Samsung 